How to Upload Table Content in Microsoft Word to Archivesspace
At University of Maryland, nosotros are migrating from a local MS Access database appropriately named the Beast. We chose to brainstorm our migration project with our accessions data. To go this data into ArchivesSpace we decided to use the csv importer since it seemed to exist the easiest format to crosswalk our data to, and honestly, the only pick for us at the time.

Okay. Allow me catch my breath.
For usa, it seemed that the lowest barrier for getting our accession data into ArchivesSpace was to employ the csv importer. Since we could get our data out of the Beast in a spreadsheet format, this made the near sense at the time. (Oh, if nosotros had only known.)
Our data was messier than we idea, so getting our data reconciled to the importer template had its fair share of hiccups. The clean-upwards is not the moral of this story, although a bit of summary may be useful: some of the problems were our own doing, such as missing accession numbers that required going dorsum to the control files, and just missing data in general. Our other major issue was understanding the importer and the template. The documentation contained some competing messages regarding the listing of columns, importance (or unimportance) ofcolumn gild, as well every bit unanticipated changes to the arrangement that were not always reflected in the csv importer and template We did finally manage to get a decent chunk of our data cleaned and in the template subsequently virtually a yr of cleaning and restructuring thousands of records.
AND Then. Just when we thought we had information technology all figured out, ArchivesSpace moved processing/processing status from collection management to events. Unfortunately, at the electric current fourth dimension there is not a way to import event information via the CSV importer. And then we were stuck. We had already invested a lot of fourth dimension in cleaning up our accessions data and at present had a pretty important piece of data that we could no longer ingest in that aforementioned fashion.
In comes the ArchivesSpace API to relieve the day!!
[In hindsight, I wish we had but used the API for accessions in the kickoff place, but when this process began we were all just wee babes and had nary a clue how to really use the API and actually idea the csv importer was the only option for u.s.a.. Oh how far we've come!]
So, we revised our process to:
- Make clean accessions in excel/open up refine
- Keep the processing information we would need to create the consequence record in a separate sail to keep the data together
- Import accessions (minus the processing issue info) using csv importer
- Afterward successful import, have a vivid-eyed student worker (thank you Emily!) practice the thankless task (pitiful Emily!) of recording the ID of each accession (which the API volition need to associate the processing outcome with the correct accession) into that split sheet mentioned in step 2
- Using the spreadsheet from pace 4 equally the source, create a spreadsheet that includes the accretion id and associated processing condition with the rest of the information required for importing events (Getting to know the various ArchivesSpace data schemas is important). To make life easier, you may want to just proper name the columns according to the schema elements to which they will map.
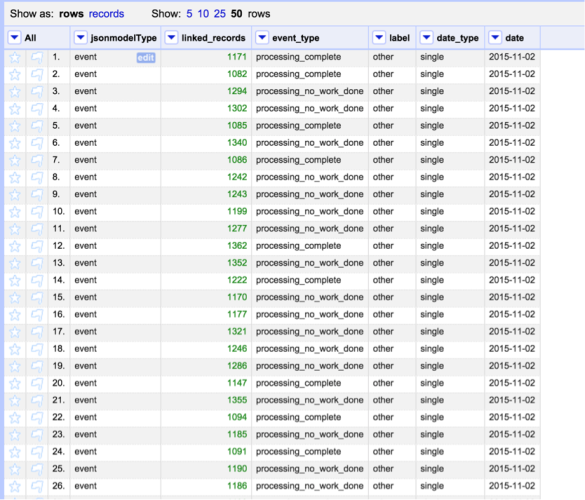
- Since the API wants this to be in a JSON file, I so upload this spreadsheet file into OpenRefine (see screenshot above). This gives me a hazard to double bank check data, but nigh importantly, makes it REALLY like shooting fish in a barrel for me to create the JSON file (I am not a programmer).
- One time I am happy with my data in OpenRefine, I go to consign, templating, then I put in the custom template (run across beneath) I've created to friction match data schemas (listed in step five). Since some is boilerplate, I didn't need to include it in the spreadsheet.
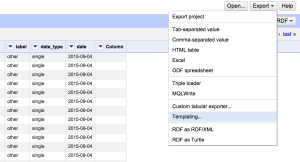
Here'southward the template I developed based on the schemas for event, engagement, and linked records:
{"jsonmodel_type":{{jsonize(cells["jsonmodelType"].value)}},"event_type":{{jsonize(cells["event_type"].value)}},"external_ids":[],"external_documents":[],"linked_agents":[{"role":"executing_program","ref":"/agents/software/1"}],"linked_records":[{"role":"source","ref":"/repositories/2/accessions/{{jsonize(cells["linked_records"].value)}}"}],"repository":{"ref":"/repositories/ii"},"date":{"label":{{jsonize(cells["characterization"].value)}},"date_type":{{jsonize(cells["date_type"].value)}},"expression":{{jsonize(cells["engagement"].value)}},"jsonmodel_type":"date"}}
So export! Make certain to salve the file with a memorable filename.
I then open the file in a text editor (for me, TextWrangler does the pull a fast one on) and I have to practise ii things: make sure all whitespaces take been removed (using observe and replace), and make sure in that location is one json per line. (regex find and supercede of \r). Still, you should be able to create the template in such a way equally to practise this.
Then, I put together a picayune bash script that tells curl to accept the json file that was just created, read it line by line and Mail service each line via the API.
#!/bin/bash url="http://examination-aspace.yourenvironment.org:port/repositories/[repo#]/result" for line in $(cat your_events.json); do echo `scroll -H "10-ArchivesSpace-Session: $TOKEN" -d "$line" $url`; done
Now, I only transfer demand to transfer both the fustigate script and the json file from my local files to the archivespace server. (using the control scp <filename> <location>. If y'all're similar me, you may accept needed to ask a sysadmin how to do this in the start place).
Brand certain yous accept logged in, and exported the Session ID every bit a $TOKEN. (I won't walk you through that whole process of logging in, since Maureen outlines it so well here, as does the the Bentley here.)
Now, from the command line, all you need to do is:
fustigate curl_json.sh
And there yous become. Y'all should run across lines streaming past telling you that events have been created.
If you don't…or if the messages you encounter are of mistake and non success, fright non. Come across if the message makes sense (often information technology will be an upshot with a difficult-to-catch format fault in the json file, like a missing semi-colon, or an extra '/' (I speak from experience). These are not always easy to suss out at first, and trust me, I spent a lot of time with trial and error to effigy out what I was doing wrong (I am not a programmer, and still very, very new at this).
Figuring out how to get our processing event data into ArchivesSpace after striking a major roadblock with the csv importer however feels similar a bully achievement. We were initially worried that we were going to have to either a) go without the data, or b) enter it manually. And then to detect a solution that doesn't require too much manual work was satisfying, professionally speaking (did I mention I'yard not a programmer and had never really dealt with APIs before?).
So to all of you out there working in ArchivesSpace, or in anything else, and you feel similar you go along hitting a wall that's a bit college than what yous've climbed before, keep at it! You'll exist amazed at what y'all can do.
Maybe this is a familiar problem for some other archivists. You have a drove that you've but finished processing — maybe it's a new conquering, or maybe information technology's been sitting effectually for awhile — and yous have some boxes of weeded papers leftover, waiting to be discarded. But for some reason — a reason ordinarily falling exterior of your job purview — you are not able to discard them. Peradventure the gift agreement insists that all discards exist returned to the donor, and you can't runway down the donor without inviting another accretion, and you but don't accept time or infinite for that right now. Maybe your library is about to renovate and movement, and your curators are preoccupied with trying to install 10 exhibitions simultaneously. Maybe the acquisition was a loftier-value gift, for which the donor took a generous tax deduction, and your library is legally obligated to keep all parts of the souvenir for at least 3 years. Maybe your donor has vanished, the gift agreement is non-real, or the discards are really supposed to go to some other institution and that establishment isn't ready to pay for them. The reasons don't matter, really. Y'all have boxes of archival fabric and y'all need to rails them, but they aren't a role of your archival collection any more. How do you manage these materials until the glorious day when y'all are actually able to discard them?
Nosotros've struggled with this at Knuckles for a long time, only it became a more pressing outcome during our recent renovation and relocation. Boxes of discards couldn't just sit in the stacks in a corner anymore; we had to ship them to offsite storage, which meant they needed to be barcoded and tracked through our online catalog. We ended up attaching them to the collection record, which was non ideal. Because the rest of the drove was candy and bachelor, nosotros could not suppress the discard items from the public view of the catalog. (Discards Box 1 is not a pretty thing for our patrons to see.) Plus, information technology was besides like shooting fish in a barrel to attach them to the collection and and then forget almost the boxes, since they were out of sight in offsite storage. At that place was no piece of cake way to regularly collect all the discard items for curators to review from across all our collections. It was messy and hard to use, and the items were never going to actually exist discarded! This was no skilful.
I ended upward making a Discards 2015 Collection, which is suppressed in the catalog and therefore not discoverable by patrons. All materials identified for discard in 2015 will be attached to this record. I besides made an internal resources record in Archivists' Toolkit (before long to be migrated to ArchivesSpace) that has a series for each collection with discards we are tracking for the year. It is linked to the AT accession records, if possible. In the resource record's series descriptions, I tape the details almost the discards: what is existence discarded, who processed it, who reviewed information technology, why we haven't been able to discard information technology immediately, and when we expect to exist able to discard the material (if known). The Discard Collection'due south boxes are numbered, barcoded, and sent to offsite storage completely separated from their original collection — as information technology should be. No co-mingling, physically or intellectually! Plus, all our discards are tracked together, so from now on, I can remind our curators and other relevant parties at regular intervals about the boxes sitting offsite that demand to be returned, shredded, sold, or whatsoever.
I'd love to hear other approaches to discards — this is a new strategy for u.s., and so perhaps I've missed something obvious that your institution has already solved. Allow me know in the comments. Happy weeding, everyone!
I'm here to talk about boxes. Get excited.
I've been spending a LOT of time lately thinking about containers — fixing them, modelling them, figuring out what they are and aren't supposed to do. And I've basically come to the decision that as a whole, we spend too much fourth dimension futzing with containers considering we haven't spent enough time figuring out what they're for and what they do.
For instance, I wrote a blog postal service a couple of months agone about work nosotros're doing to remediate stuff thatshould non onlyis happeningwith containers — barcodes being assigned to 2 dissimilar containers, ii unlike container types with the same barcode/identifier information, etc. Considering the scale of our collections, the calibration of these problems is mercifully slight, simply these are the kinds of problems that plough into a crisis if a patron is expecting to find material in the box she ordered and the material merely isn't there.
I'm besides working with my colleagues here at Yale and our ArchivesSpace development vendor Hudson Molonglo to add functionality to ArchivesSpace so that it's easier to piece of work with containers equally containers. I wrote a blog post about it on our ArchivesSpace blog. In brusque, we desire to make information technology much easier to practice stuff like assigning locations, assigning barcodes, indicating that container information has been exported to our ILS, etc. In lodge to do this, we need to know exactly how we want containers to relate to archival clarification and how they relate to each other.
Equally I've been doing this thinking nearly specific container issues, I've had some thoughts near containers in general. Here they are, in no particular order.
What are container numbers doing for us?
A container number is simply a human-readable barcode, right? Something to uniquely identify a container? In other words, speaking in terms of the data model, isn't this data that says something dissimilar but means the same thing? And is this possibly a point of vulnerability? At the end of the day, isn't a container number something that we train users to care nearly when really they want the content they've identified? And we have a much ameliorate system for getting barcodes to uniquely identify something than we do with box numbers?
In the days that humans were putting box numbers on a phone call slip and some other human was reading that and using that information to interpret shelf location, information technology made sense to ask the patron to be explicit most which containers were associated withthe actual thing that they desire to see. Simply I remember that we've been too skilful at training them (and training ourselves) to think in terms of box numbers (and, internally, locations) instead of creating systems that do all of that on the back stop. Data about containers should exist uniform, unadorned, reliable, and interact seamlessly with information systems. Boxes should exist stored wherever is best for their size and climate, and that should be tracked in a locations database that interacts with the requesting database. And the actual information should be associated seamlessly with containers.
This means that instead of writing downwardly a call number and box number and reading a note about how materials of this type are stored on-site and materials of another type are stored off-site, allow'southward take a lot of human error out of this. Let'south allow them merely click on what they want to see. Then, the organisation says "a-ha! In that location are so many connections in my database! This tape is in box 58704728702861, which is stored in C-29 Row eleven, Bay 2, Shelf 2. I'll send this to the queue that prints a call slip and then a page can go that correct away!" And instead of storing box numbers and folder numbers in the person'south "shopping cart" of what she'due south seen, permit'due south store unique identifiers for thearchival clarification, so that if that same record get's re-housed into box 28704728702844 and moved to a different location, the patron doesn't have to update her commendation in any scholarly work she produces. Even if the collection gets re-processed, we could make certain that identifiers for stuff that's truly the same persists.
Also, don't tell me that box numbers do a proficient job of giving cues about order and scale. There are waaaaaayyyyy better ways of doing that than making people infer relationships based on how much material fits into 0.42 linear feet.
Nosotros have the concepts. Our practice needs to take hold of upward, and our tools do too.
Darn it, Archivists' Toolkit, you do some dumb things with containers
Archival management systems are, apparently, a huge pace upward from managing this kind of information in disparate documents and databases. But I remember that we're still a few years away from our systems meeting their potential. And I really remember that folks who do deep thinking almost archival description and standards development need to insert themselves into these conversations.
Here's my favorite example. You lot know that affair where yous're doing description in AT and you want to associate a container with the records that you merely described in a component? You know how it asks you what kind of an instance you want to create?That is non a affair.This is just role of the AT data model — there'south nothing like this in DACS, nil like information technology in EAD. Actual archival standards are smart enough to not say very much about boxes because they're boxes and who cares?When it exports to EAD, it serializes as @label. LABEL. The pinnacle of semantic nothingness!
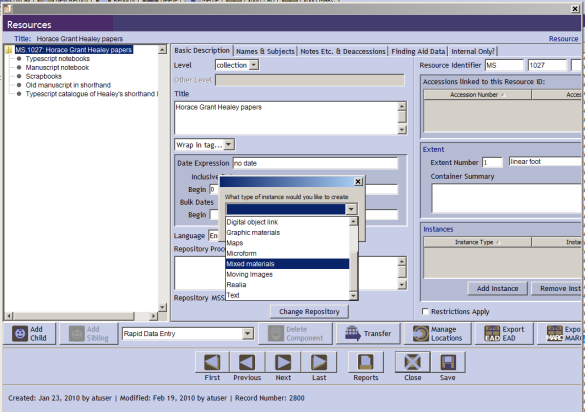
This is non a thing.
Like, WHY? I can see that this could exist the moment where AT is asking y'all "oh, hey, do you want to acquaintance this with a physical container in a concrete place or practise y'all want to associate it with a digital object on teh interwebz?" but there'southward probably a better way of doing this.
My problem with this is that information technology has resulted in A LOT of descriptive malpractice. Practitioners who aren't familiar with how this serializes in EAD think that they're describing the content ("oh yes! I've done the equivalent of assigning a grade/genre term and declaring in a meaningful manner that these are maps!") when really they've put a label on the container. The container is non the stuff! If you want to describe the stuff, y'all exercise that somewhere else!
Oh my gosh, my assertion betoken count is pretty high right now. I'll see if I can pull myself together and soldier on.
Peradventure we should be more explicit about container relationships.
Now, popular quiz, if y'all take something that is in the physical collection and has also been microfilmed, how do you indicate that?
In Archivists' Toolkit, there's zip clear about this. You can acquaintance more than than one instance with an archival description, but yous can also describe levels of containers that (ostensibly) describe the same stuff, but happen to be a numbered item within a binder, within a box.
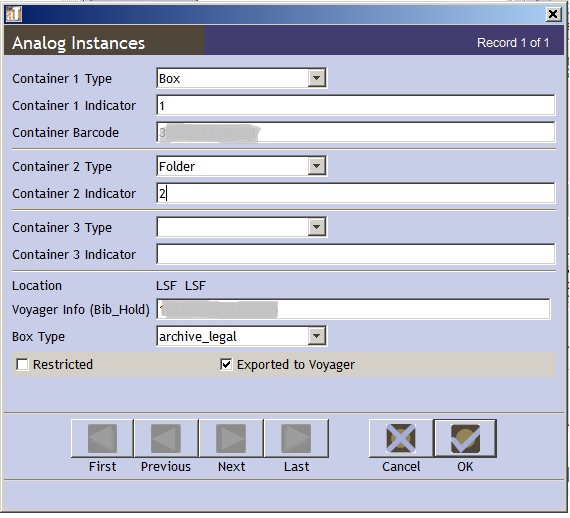
Anything can happen here.
So this means that in the scenario I mentioned above, it often happens that someone will put the reel number into container 3, making the database recall that the reel is a kid of the box.
But fifty-fifty if all of the data entry happens properly, EAD import into Archivists' Toolkit will have any 3 <container> tags and instead of making them siblings, brings the three together into parent-child instance relationship like you lot see above. This helps maintain relationships between boxes and folders, only is a nightmare if you lot have a reel in there.
EAD has a way of representing these relationships, simply the AT EAD consign doesn't really even practice that properly.
<c id="ref10" level="file"> <did> <unittitle>Potter, Hannah</unittitle> <unitdate normal="1851/1851">1851</unitdate> <container id="cid342284" blazon="Box" label="Mixed Materials (39002038050457)">1</container> <container parent="cid342284" type="Folder">2</container> </did> </c> <c id="ref11" level="file"> <did> <unittitle>Potter, Horace</unittitle> <unitdate normal="1824/1824">1824</unitdate> <container id="cid342283" blazon="Box" label="Mixed Materials (39002038050457)">1</container> <container parent="cid342283" blazon="Folder">three</container> </did> </c>
Here, we come across that these box 1'southward are the same — they have the same barcode (btw, see previous posts for assist working out what to do with this crazy export and barcodes). But the container id makes it seem like these are 2 dissimilar things — they have ii different container id'south and their folders refer two two different parents.
What nosotros actually want to say is "This box 1 is the aforementioned as the other box 1's. It's not the same as reel 22. Folder 2 isinside of box i, and then is folder 3." Once we go our systems to stand for all of this, nosotros tin do much better automation, better reporting, and have a much more reliable sense of where our stuff is.
So if we want to be able to work with our containers as they actually are, we need to represent those properly in our engineering. What should we exist thinking near in our descriptive practice now that we've de-centered the box?
"Box" is not a level of description.
In ISAD(Thousand) (explicitly) and DACS (implicitly), archivists are required to explain the level at which they're describing aggregations of records. At that place isn't a vocabulary for this, but traditionally, these levels include "collection", "tape grouping", "series", "file" and "item." Annotation that "box" is not on this list or any other reasonable person'southward listing. I know everyone ways well, and I would never discourage someone from processing materials in aggregate, only the term "box-level processing" is like nails on a chalkboard to me. Equally a concept, it should not be a thing. At present, series-level processing? Consider me on board! File-group processing? Awesome, sounds good! Do yous want to break those file groups out into discrete groups of records that are often surrounded by a folder and hopefully are associated with distinctive terms, like proper nouns? Sure,if you think it will aid and you lot don't have anything better to do.
A box is usually just an blow of administravia. I truly believe that archivists' value is our ability to discern and describe aggregations of records — that box is not a meaningful aggregation, and describing information technology as such gives a fake impression of the importance of one linear foot of material. I'd actually love to see a push button toward better series-level or file-grouping-level description, and less file-level mapping, especially for organizations' records. Often, unless someone is doing a known detail search, there'south nothing distinct enough about private filesevery bit evidence (and remember, this is why we do processing — to provide access to and explain records that give prove of the by) to justify sub-dividing them. I also think that this could help us think past unnecessary sorting and related housekeeping — our chore isn't to make social club from chaos*, it's to explain records and their context of creation of use. If records were created chaotically and kept in a chaotic manner, are we really illuminating anything by prescribing artificial guild?
This kind of thinking volition be increasingly important when our records aren't tied to concrete containers.
In decision, let's go out the robot work to the robots.
If I never had to translate a telephone call number to a shelf location once more, it would be too before long (really, we don't practice that at MSSA, just still). Permit'southward end making our patrons care well-nigh boxes, and let's start making our engineering piece of work for us.
* This weblog's championship, Chaos –> Order, is not about bringing order to a chaotic past — it's about bringing gild to our repositories and to our work habits. In other words, get that beam out of your own heart, sucka, before you become your alphabetization on.
It's been tranquillity around here lately — look out for a handful of book review weblog posts next week.
Until then, if yous need a quick fix of archival order, I would encourage you to bank check out the ArchivesSpace @ Yale implementation blog here, and its companion site with associated documentation, here. I call up that all four of us have ArchivesSpace on our agendas in i way or another, so you lot'll probably be seeing more than ArchivesSpace planning blog posts on this site, too.
In my last postal service, I talked about how we have used macros at Maryland to commencement converting preliminary inventories into more useful formats to set for eventual importation to ArchivesSpace and create EAD finding aids. Using some other macro, I have replaced folder title rows containing "(2f)" or "(3f)" with multiple rows. Using these two macros together, each single line in our tables volition represent a single folder. To complete the process, I used a formula that rapidly creates binder numbers. Folder numbers will allow you lot to sort the spreadsheet information while preserving the physical order and location of each folder.
In a Discussion document, the 2f or 3f autograph might help preserve space in an inventory or finding assist, or information technology might seem more logical or aesthetically pleasing. But in a tabular array, we want an accurate representation of each unit (the folder). In the Athletic Media Relations instance that I discussed in my final post, in that location were 67 rows that contained either 2f, 3f,or 4f:

Copying these lines ane past one would take taken an excessive amount of time. Instead of copying a folder title over and over again, I automated the task past using this macro:
Sub two_f()
' Sub and Finish Sub are commands that say the macro will start and end
'Do is a command that marks the kickoff of a loop
Practise
Columns("B:B").EntireColumn.Select
'Search the B column for 2f instances
Selection.Find(What:=", (2f)", After:=ActiveCell, LookIn:=xlFormulas, _
LookAt:=xlPart, SearchOrder:=xlByRows, SearchDirection:=xlNext, _
MatchCase:=False, SearchFormat:=Fake).Activate
'Create a new line and copy down
ActiveCell.Showtime(ane, 0).Rows("1:ane").EntireRow.Select
Selection.Insert Shift:=xlDown, CopyOrigin:=xlFormatFromLeftOrAbove
Choice.FillDown
'replace the "2f" from the line you copied and line you lot pasted
ActiveCell.Offset(-ane, 1).Range("A1:A2").Select
Choice.Replace What:=", (2f)", Replacement:="", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=Imitation, SearchFormat:=Simulated, _
ReplaceFormat:=False
Loop Until Cells.findnext is nothing
Range("A1").Select
MsgBox "Conversion complete!"
Stop Sub
This macro can be adapted for instances of "(3f)", "(4f)", etc. The following code shows the appropriate adjustments:
Sub three_f()
' Sub and Finish Sub are commands that say the macro will start and end
'Exercise is a command that marks the beginning of a loop
Practice
Columns("B:B").EntireColumn.Select
'Search the B cavalcade for 3f instances
Selection.Detect(What:=", (3f)", After:=ActiveCell, LookIn:=xlFormulas, _
LookAt:=xlPart, SearchOrder:=xlByRows, SearchDirection:=xlNext, _
MatchCase:=False, SearchFormat:=Faux).Activate
'Create two new lines and re-create down each time
ActiveCell.Offset(i, 0).Rows("ane:1").EntireRow.Select
Selection.Insert Shift:=xlDown, CopyOrigin:=xlFormatFromLeftOrAbove
Option.FillDown
ActiveCell.Offset(1, 0).Rows("1:i").EntireRow.Select
Selection.Insert Shift:=xlDown, CopyOrigin:=xlFormatFromLeftOrAbove
Selection.FillDown
'supervene upon the "3f" from the line you copied and two lines you pasted
ActiveCell.Outset(-2, 1).Range("A1:A3").Select
Option.Replace What:=", (3f)", Replacement:="", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=Imitation, SearchFormat:=Faux, _
ReplaceFormat:=False
Loop Until Cells.findnext is nil
Range("A1").Select
MsgBox "Conversion complete!"
End Sub
The lawmaking could besides exist adjusted accordingly to accommodate instances of 4f, 5f, etc. The macros will make the post-obit adjustments to our example:

Within a few seconds, the macro created about 200 lines in this Able-bodied Media Relations spreadsheet.
As with any macro that yous might copy and paste into your VBA Projection Window, relieve frequently and make sure this fits your needs exactly to prevent whatever unintended results. For example, the sample lawmaking higher up searches for and replaces "(3f)", but your inventories might not use parentheses.
Now that each line in this tabular array represents a single folder in this collection, we should create a binder number to preserve the order inside each box.
Formulas accept been used elsewhere on this blog. Like macros, formulas are extremely powerful for data cleanup and this i will hopefully requite y'all some inspiration. Every bit Cassie has written earlier, the IF formula can be very useful for testing a condition of your choice for a column of information. It can also exist used for creating new data. In this case, I want to create a folder number.
This formula uses the same If/Then/Else logic as Cassie's previous example. The =IF command requires three statements separated past commas. The get-go ("If") is the true or faux condition you are testing. The second ("Then") is the outcome yous desire if the condition has been met; the third ("Else") is the result that y'all want if the condition was not met.
In this formula, nosotros want to see if a folder is in the aforementioned box equally the previous folder. If information technology is, nosotros want to proceed a sequence of folder numbers (i to two, 2 to 3, etc.). If this folder is non in the aforementioned box, we desire to reset the sequence of binder numbers and start over with the number 1 ("ane").
In the Excel IF formula, this logical expression looks like this:
=IF(A2=A1,B1+i,1)
The one problem hither is that this formula volition not piece of work for your very first binder, since it has no previous line to refer back to. To resolve this, but put the number "i" as your first folder number and put the formula in the cell for the second binder number.

After you striking enter, fill down and don't forget to copy the cells, and Paste Special your values!
As with macros, assistance with formulas is easy to find through Google, particularly on sites such every bit MrExcel.com or StackOverflow.
At University of Maryland nosotros have lots of folder- (or item-) level inventories for candy, partially candy, or unprocessed collections. Preliminary inventories were more often than not created using Microsoft Word, which is meant to create written works on printed pages, not the tabular data that nosotros need to operate betwixt systems. Complicating matters further, these files were each structured quite differently. My challenge this summer was to bring some of these Word documents into a standardized tabular array format. Getting this information into Excel is a first step before we can apply it in an EAD finding aid/ArchivesSpace. This has required quite a bit of cleanup and conversion. By using macros and formulas, nosotros tin make the conversion process a little easier.
I started the conversion process using many of the same regular expressions that Bonnie has described hither on the blog. I peculiarly looked out for tabs and line breaks, which you can locate in Word by searching for ^p or ^t (as well every bit ^13 and ^nine, if you are using wildcards). To convert the inventory into a table, I had to make sure that each folder title was separated by ane line suspension, with no line breaks in betwixt. This would allow me to re-create and paste the contents of the Discussion certificate into Excel and create a clean table.
Cleaning up a Discussion document with regular expressions was merely part of the conversion process. I was withal left with a number of redundant tasks moving around standardized data in Excel. First amongst them was to eliminate lines reporting a box number and move that number into a separate column. This is where I started introducing macros into our conversion work.
A Microsoft Office macro is essentially a procedure that automatically executes a chore or series of tasks. You tin can run one by clicking an option on a list or even pressing a custom-fabricated hotkey. Microsoft Part macros employ Visual Basic for Applications (VBA) programming linguistic communication. VBA is intended to be a simple, forgiving language, but it still takes some time to learn. I volition point out a few unproblematic steps you can accept to become started with macros and even how to customize each code.
The simplest manner to create a macro is to record it. Microsoft Word and Excel tin can "tape" your actions by translating your activeness in the program into a written code. You can then save these actions and re-create them later on by "playing" the macro.
To tape a macro, become to the View tab, click on the Macros list, and click "Record Macro." When you are finished recording, go back to the Macros listing and click "Stop Recording." To replay the macro (re-run the aforementioned operations you recorded) or edit the source lawmaking, go to the Macro list and click View Macro, then "Run" or "Edit".
In some instances, yous may already have the code for a macro but practice not have it stored into your copy of Microsoft Excel. To insert the pre-written code into Excel, type Alt+F11 to open up the VBA Projection Window, then Insert -> Module. Paste your code into the new window and press the Play button.
The example that I will apply is from ane of our Athletic Media Relations accessions. If I were to motility the words "Box 5" manually, I would perform a series of steps: search for "Box 5", copy the jail cell contents, delete the row, find an next empty cell to paste the value "5", and fill "five" downwardly. I wanted to plough this:

into this:
This particular inventory only had thirteen boxes, and could exist converted in a minute or two manually, but that could accept a very long time if you have a preliminary inventory with hundreds of boxes. So far I have applied the macro to nigh thirty inventories comprising several hundred boxes and saved hours of work. I used the following code to automate the process:
Sub Macro1()
' Sub and End Sub are commands that say the macro volition get-go and end
'Create a new A column for the box number
Columns("A:A").Select
Selection.Insert Shift:=xlToRight, CopyOrigin:=xlFormatFromLeftOrAbove
'Take the value Box 1 from Cell B1 to Jail cell A1
ActiveCell.First(0, one).Range("A1").Select
Selection.Cut
ActiveCell.Offset(0, -1).Range("A1").Select
ActiveSheet.Paste
'Fill up the box number down
Selection.Copy
Range(Selection, Option.Cease(xlDown)).Select
ActiveSheet.Paste
'Delete the row that initially had Box 1 in it
Rows(1).Delete
Columns("B:B").Select
'Do is a command that marks the beginning of a loop
Do
'Selection.Find searches within the selection (the B column) for a jail cell with a box number
Choice.Detect(What:="box *", Subsequently:=ActiveCell, LookIn:=xlFormulas, _
LookAt:=xlPart, SearchOrder:=xlByRows, SearchDirection:=xlNext, _
MatchCase:=False, SearchFormat:=Faux).Activate
ActiveCell.Select
Pick.Cut
ActiveCell.First(0, -i).Select
ActiveSheet.Paste
'Take out the word box in the A column so it is just a number
Columns(1).Cells.Replace What:="Box ", Replacement:="", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=Fake, _
ReplaceFormat:=False
Selection.Copy
Range(Selection, Choice.Cease(xlDown)).Select
ActiveSheet.Paste
ActiveCell.Rows("1:ane").EntireRow.Select
Application.CutCopyMode = Fake
Selection.Delete Shift:=xlUp
Columns("B:B").Select
'This statement causes the commands to echo until there are no more cells with the word Box in it
Loop Until Cells.FindNext Is Nothing
'These final five lines clean up the leftover box number from the last fill down
Selection.Terminate(xlDown).Select
ActiveCell.Offset(1, -1).Select
Range(Selection, Selection.End(xlDown)).Select
Option.ClearContents
Range("A1").Select
'End Sub is a required control that ends the macro
End Sub
Before y'all press "play," a few words of warning. Get-go, make sure you save a backup re-create. You lot cannot undo the changes that are made through a macro! Any existing VBA lawmaking may need minor changes and tweaks to piece of work with a new document, so be careful to review your code and brand certain it fits your needs. Besides, cheque to meet if the macro will produce any unintended results when it runs.
The above sample macro identifies the "Box x" field by searching for the give-and-take "box" followed by a space and more characters. And then brand certain that there are no folder titles with the word "box" in information technology! (For instance, in the sample screenshots above, "Box Scores" would need to be changed to read "Box-Scores".)
For additional macro and VBA tips and workarounds, search Google for using "Excel", "macro" and "VBA" equally search terms. MrExcel.com and StackOverflow are particularly useful sites.
In the next blog post, I will introduce a few other Excel macros and functions nosotros have used at Maryland to continue this conversion process.
One morn recently, our records services archivist sent me an email. He was wondering if there was a way I could report to him on which materials in our university archives have restrictions that have passed. After all, this data is buried in access restriction notes all over finding aids — it would be very hard to find this information by doing a search on our finding aids portal or in Archivists' Toolkit.
This is exactly the kind of project that I dear to do — it's the intersection of archival functions, improved user feel, and metadata ability tools.
In ArchivesSpace, restrictions take controlled appointment fields. This kind of study would be very piece of cake in that kind of environment! Unfortunately, AT and EAD only has a identify for this data as free text in notes.
Time for an xquery!
xquery version "3.0"; declare namespace ead="urn:isbn:1-931666-22-ix"; declare namespace xlink = "http://world wide web.w3.org/1999/xlink"; declare namespace functx = "http://www.functx.com"; <restrictions> { for $ead in ead:ead allow $physician := base-uri($ead) return <document uri="{$doc}"> { for $accessrestrict in $ead//ead:dsc//ead:accessrestrict/ead:p[matches(.,'(19|twenty)[0-nine]{2}')] let $series := $accessrestrict/antecedent::ead:c[@level = 'series' or @level = 'accretion' or @level = 'accn']//ead:unitid let $dateseg := fn:substring-after($accessrestrict,'until') for $x in $serial return <lookhere location="{$ten}"> {$accessrestrict} <date>{$dateseg}</date> </lookhere> } </document> } </restrictions> And at present for the walk-through.
Working together, we determined that any end dates will exist below the <dsc>. So this written report asks for whatever access restriction note beneath the dsc that includes a date in the twentieth or 20-first century.
The study tells me what series that admission brake note is a part of and which file it's a part of. I besides pull out any text after the word "until", because I run into that common exercise is to say "These materials will be restricted until XXXX."
From in that location, I was able to put this data into an excel spreadsheet, do a chip of clean-upwards at that place, and give my colleague a sorted list of when particular series in collections are slated to be open.
If y'all've ever used curl before, you lot don't demand this.
Also, the videos and documentation that Hudson Molonglo put together are really stellar and recommended to anyone starting with this.
This guide is a true projection-pad of my notes of how I did this. It might as well be useful for those of usa who never had formal grooming with scripting, just are in charge of the archival information in our repositories and appreciate power tools. Plainly, the trouble with power tools is that y'all tin can cut your arm off. Apply this carefully. Use in test/dev. Inquire someone to check your work if y'all're doing something truly crazy.
Here's what I did
This came up for me because I had done a failed test migration (we think at that place's a weird timestamp trouble in the accessions table) and I wanted to delete the repository and all records in the repository in ASpace before trying again. As far as I can tell, there isn't a bang-up way to delete thousands of records in the user interface. And so, the API seemed the way to go.
I figured this out past watching the video and reading the documentation on GitHub, and and so doing a little actress googling effectually to learn more about curl options.
If you're using a Mac, merely fire upwardly the terminal and become on with your life. I use a Windows PC at piece of work, so I use Cygwn every bit a Unix emulator. The internet gave me skillful communication most how to add curl.exe.
Note: y'all won't exist able to do any of this unless you take admin access.
Allow's first with "Hello, World!"
$ curlicue 'http://test-aspace.yourenvironment.org:port/'
In this case, the url before the colon should exist your ASpace example (utilize exam/dev!) and "port" should be your port. The response you get should basically only tell you that yes, you have communicated with this server.
Connect to the server
$ coil -F password='your password' 'http://test-aspace.yourenvironment.org:port/users/admin/login'
Hither, y'all're logging on as admin. The server will respond with a session token — go ahead and re-create the token response and make it a variable, so you don't have to keep rail of it.
export TOKEN=cc0984b7bfa0718bd5c831b419cb8353c7545edb63b62319a69cdd29ea5775fa
Delete the records
Here, you definitely want to check the API documentation on GitHub. Basically, this tells you how to format the URI and the control to employ. For example, beneath, I wanted to delete an entire repository. I found out, though, that I couldn't delete the repository if it had records that belonged to it. Since agents and subjects exist in ASpace without belonging to a repository, and since accessions and digital records hadn't successfully migrated, I only needed to delete resource records.
$ curl -H "X-ArchivesSpace-Session: $TOKEN" -X "DELETE" 'http://examination-aspace.yourenvironment.org:port/repositories/iii/resources/[278-1693]'
And so, I passed something to the header that gave my token ID, then I sent a command to delete some records. But which ones?
Allow's parse this URI. The first part is my ASpace exam server, the port is my port.
The next thing to understand is that each repository, resource, accretion, agent, whatever, has a numeric ID. URIs are formatted co-ordinate to the tape type and the ID. So, I go to repositories/3, because the resources I want to delete are in a particular repository, and that repository has the numeric ID of "3". In order to find this out, y'all tin can look in the ASpace interface, or yous can ship a call to yoururl/repositories, which will requite you lot a json response with id (and other) information nearly all of the repositories on your server.
After that, I tell curl which resources records I desire to delete. In that location'south probably a meliorate way, merely I figured this out by sorting resources by engagement created, both ascending and descending, to detect out what the first and final IDs are. I'd imagine, though, that if I didn't want to look that upwards and I merely asked for
'http://test-aspace.yourenvironment.org:port/repositories/3/resources/[1-2000]'
I would probably be okay, because it's only deleting resources records in repository 3 and I want to get rid of all of those anyway. I'd get an error for resources that don't exist in that repository, but it wouldn't break anything. I had wondered if there are wildcards for curl, so that I could go Whatever number after resources, but (according to some brief googling) it doesn't wait like there are.
What does this all hateful?
Uh, I don't know? I mean, the API is obviously very powerful and amazing, and I'm glad I didn't have to figure out a way to delete those records in the interface. But I'm actually just starting to dip my toe into the potential of this. I'm certain you tin can await forward to more updates.
I could have titled this mail service "Why Accessioning Information Matters" too. You may recall back to my first post about the Creature I included a lovely map of the fields and tables.
I didn't talk in peachy depth about all the associated problems, but one of the biggest challenges migrating data out has been the archdescid tabular array. In some respects, it'due south easy as most of the fields brand sense, have a clear field to map to in ArchivesSpace, and we have ways to clean up the data when it's in the wrong spot. However, one of the hardest quirks is that the archdescid table includes both accessions and resources (aka collection) information in the aforementioned table and fields.

Archdesc table from Beast Database on the wall. First brainstorming of accession/resource records.
Staff admission the data through 2 different front end end forms in Access. The "accessions form" and the "finding aid grade" pull diverse fields to display. Not all fields are available in both forms, just all the information is stored in the same identify.
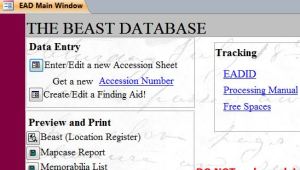
Staff view of Beast to enter accessions or finding aid information.
This means in the process of creating a finding aid accessions information is OVERWRITTEN. (Part of this is likewise due to the fact that nosotros haven't used divide "collection numbers", but instead utilize the earliest accession number to identify a group of materials. This took away a necessary step of creating a new tape for a finding help.) Sometimes overwriting information is fine because maybe nosotros had sketchy dates and now nosotros accept better ones. Just, sometimes this ways we are overwriting very specific accessions information with aggregate information almost a larger set up of materials meant for a finding assistance.
For example, maybe we go the beginning installment of Sally Smith's papers of two linear anxiety in 2002 and create an accession tape to certificate that donation. By 2010, nosotros've gotten three more accretions and decided to process all four accessions together and create a finding assist. Our finding aid is built from the 2002 tape in the Brute.
It's at present 2014 and nosotros just got another accretion. We create the 2014 accession record and decide to add the materials right abroad to the processed drove. Because of how the archdescid table is set every fourth dimension we added information to the Emerge Smith papers finding assist we altered the accretion tape for the 2002 accretion as the data in that record serves as our finding assistance information too. By the fourth dimension we're washed adding in our 2014 materials, the 2002 accretion record now says 25 linear feet, the volume of all v accessions together. Nosotros accept now lost the specific accessions information for the oldest accession for this collection (unless it happens to alive on paper buried in control files.)
So the question is, how do we retroactively create accession records from a maybe aggregate finding assistance?
We accept two major categories of these accessions:
- Records where we recollect the finding assistance but represents ane accession.
- These range in size from a few items to virtually 100 linear feet. Nosotros're pretty confident that the information for smaller collections equates to accessions, but can't be sure and who knows what the real correlation to size is.
- Records where we know there are additional accretions.
- Accretions may or may not be represented in the finding aid. Sometimes we tracked this, sometimes we didn't. If we tracked it, we did it in different means. Sometimes we know that some of the accretions were added and others weren't. Or that some were and are unsure of the others. In that location'due south lots of variation here.
We spent a practiced chuck of fourth dimension analyzing these records trying to determine what information was reliable for accessions. Here's what nosotros remember is by and large reliable:
- Title
- Accession number
- Accretion date (In that location are little to no accession dates supplied for these records, so most volition inherit the default date)
- Dates of materials
- Admission and utilize restrictions
- Donor proper noun and contact data
Information that's more than of a crap shot:
- Extents
- Contents description (will populate from a combo of our abstract and scope notes, includes lots of bio info, going to be messy and not ideal)
Solution for now:
Import these accession records with the information bachelor knowing that for some (most?) the information doesn't accurately document the accretion.
Add together a general note to explicate the data. Something similar "This accession tape was created from an aggregate finding help and may not stand for accurate accessions information. Accession specific data may be bachelor in control files."
Go along to refine data as accessions/resources are worked on through our normal processing/prioritization workflows.
What would you do? Have others dealt with a similar problem?
Information technology's been a while since I terminal posted, and in that location'south a good reason for that — I've started an heady new job equally an archivist and metadata specialist at Yale. I miss my colleagues and friends at Tamiment every day, and I look forrad to continued awesome things from them.
Here at Yale, I work in Manuscripts and Archives. The major project for the kickoff year will be to migrate from Archivists' Toolkit to ArchivesSpace. In anticipation of this migration, I'thou learning about the department's priorities for data clean-up and thinking through what I can practise to assistance implement those goals.
The Goals
One of the first projects that was added to my listing was to take a wait at a project that has been ongoing for a while — cleaning up known errors from the conversion of EAD 1.0 to EAD 2002. Much of the work of fixing bug has already been done — my boss was hoping that I could do some reporting to make up one's mind what problems remain and in which finding aids they can be establish.
- Which finding aids from this projection have been updated in Archivists' Toolkit just take not yet been published to our finding help portal?
- During the transformation from 1.0 to 2002, the text inside of mixed content was stripped (bioghist/blockquote, scopecontent/blockquote, scopecontent/emph, etc.). How much of this has been stock-still and what remains?
- Container information is sometimes… off. Folders will exist numbered 1-due north beyond all boxes — instead of Box 1, Folders 1-20; Box 2, Folders 1-15, etc., we have Box 1, Folders ane-20; Box ii, Folders 21-35.
- Because of changes from 1.0 to 2002, information technology was common to have duplicate arrangement information in 1.0 (once equally a table of contents, once as narrative information). During the transformation, this resulted in two arrangement statements.
- The content of <title> was stripped in all cases. Where were <title> elements in i.0 and has all the work been done to add together them back to 2002?
- See/Meet Also references were (strangely) moved to parent components instead of where they belong. Is there a way of discovering the extent to which this problem endures?
- Notes were duplicated and moved to parent components. Once again, is at that place a way of discovering the extent to which this trouble endures?
Getting to the Files
Admission to files that take been published to our portal is like shooting fish in a barrel — they're kept in a file directory that is periodically uploaded to the web. And I besides take a cache of the EAD one.0 files, pre-transformation. These were both easy to pull down copies of. Simply, one of the questions I was request was how these differ from what's in the AT. It's so, so easy to brand changes in AT and forget to consign to EAD.
If any of you know adept ways to batch export EAD from AT, Please Permit ME KNOW. I take a pretty powerful motorcar and I know that folks here have worked on optimizing our AT database, simply I could only export about 200 files at a fourth dimension, for fright of the awarding hanging and somewhen seizing up. So, I ran this in the groundwork over the course of several days and worked on other stuff while I was waiting.
For some analyses, I wanted to exclude finding aids that aren't published to our portal — for these, I copied the whole corpus to a divide directory. To get a list of which finding aids are internal-only, I very simply copied the resources record screen in AT (you tin customize this to show internal-simply finding aids as a column), which pastes very nicely into Excel.


In one case in Excel, I filtered the list to get a listing of Internal Simply = "Truthful". From there, I used the same technique that I had used to kill our zombie finding aids at NYU. I made a text document called KillEAD.txt, which had a list of the internal-simply finding aids, and I used the control
true cat KillEAD.txt | tr -d '\r' | xargs echo rm | sh
to expect through a list of files and delete the ones that are listed in that text document. (In case yous're wondering, I'm now using a Unix simulator called Cygwin and there are weird things that don't play nicely with Windows, including the fact that Windows text documents append /r to the ends of lines to indicate carriage returns. Oh, also, I put this together with spit and bailing wire and a google search — suggestions on better ways to exercise this kind of thing are appreciated).
So, that's step 0. Don't worry, I'll be blogging my approach to goals 1-7 in the days ahead. I have some ideas about how I'll practice much of it (1, three, and 4 I know how to assess, ii I have a harebrained plan for, 5-7 are still nascent), but any suggestions or brainstorming for approaching these problems would be MORE THAN WELCOME.
Source: https://icantiemyownshoes.wordpress.com/category/archivesspace/
0 Response to "How to Upload Table Content in Microsoft Word to Archivesspace"
Post a Comment